从 URL 到浏览器渲染完成
学完计算机网络到现在(感觉已经全部还给老师了),对于输入URL到浏览器渲染完成显示页面这个过程一直都只是一个比较模糊的概念,今天有空总结一下。
模糊概念
当你输入指定的URL(Uniform Resource Locator统一资源定位符)并按下回车,浏览器就开始干活了
DNS域名解析- 建立
TCP连接 - 发送
HTTP请求 - 服务器处理请求
- 返回响应结果
- 关闭
TCP连接 - 浏览器解析
HTML - 浏览器渲染页面
以上8个过程,我大致分为两个部分:网络连接通信和页面渲染,进行详细了解
网络连接通信
每个网络设备间的通信都遵循TCP/IP协议,利用TCP/IP协议族进行网络通信时,会通过分层顺序与对方进行通信。TCP/IP模型分层自上而下分别为:应用层、传输层、网络层、数据链路层、物理层。发送端从应用层往下走,接收端从底层往上走。
输入 URL
用户输入的URL可以为域名或IP地址,使用域名是为了方便记忆,但是为了让计算机理解这个地址还需要把它解析为IP地址。上面我说到,当用户输入URL并按下回车,浏览器才开始工作其实是不正确的,现在主流浏览器引入了DNS预取技术。 浏览器为了加快域名DNS解析速度,会对网页的所有链接先做域名解析。所以,当用户在输入指定URL的时候,浏览器其实已经在本地缓存模糊搜索URL了,然后智能提示并助于用户补全URL,并且在用户还没有按下回车键的时候,浏览器就已经开始使用DNS预取技术解析该域名了。
DNS 域名解析
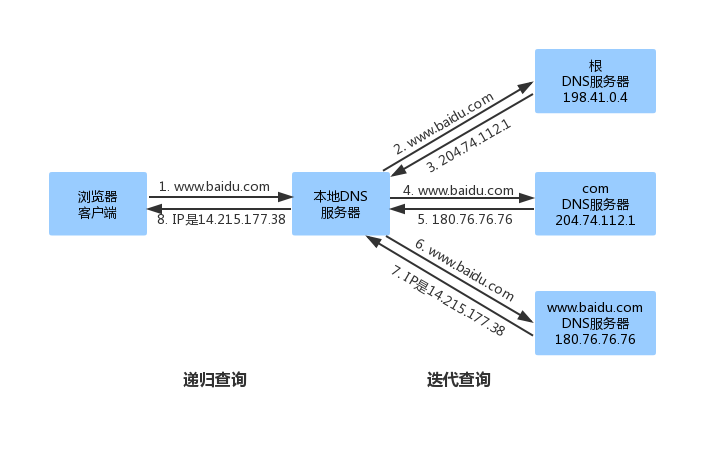
- 浏览器客户端收到你输入的域名地址后,首先浏览器搜索自己的
DNS缓存,其次是系统缓存,接着到本地的hosts文件查找有没有对应的域名映射,如果有,则向其IP地址发送请求 - 以上都没有找到对应的域名映射,再去找
DNS服务器 - 浏览器客户端向本地
DNS服务器发送一个含有域名www.baidu.com的DNS查询报文 - 本地
DNS服务器把查询报文转发到根DNS服务器,根DNS服务器分析其后缀,然后向本地DNS服务器返回其后缀的服务器的IP地址,这里返回comDNS服务器的IP地址 - 本地
DNS服务器再次向comDNS服务器发送查询请求,comDNS服务器注意到其www.baidu.com后缀并用负责该域名的权威DNS服务器的IP地址作为回应 - 负责该域名的权威
DNS服务器解析该域名映射的IP地址并返回本地DNS服务器 - 最后,本地
DNS服务器将含有www.baidu.com的IP地址的响应报文发送给客户端
建立 TCP 连接
TCP 是一种面向有连接的传输层协议。它可以保证两端(发送端和接收端)通信主机之间的通信可达。它还能够处理在传输过程中丢包、传输顺序乱掉等异常情况,以及有效利用宽带,缓解网络拥堵。
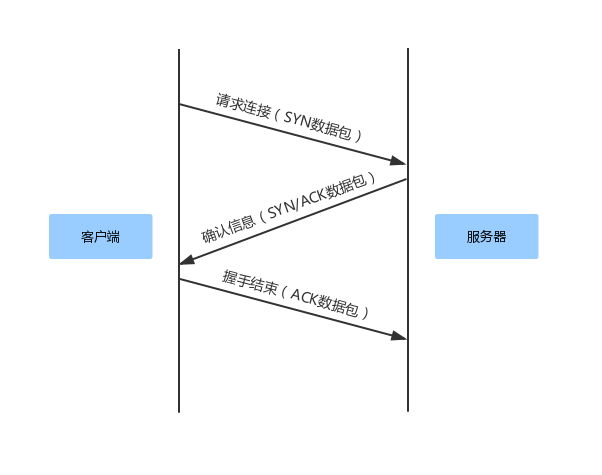
SYN :在连接建立时用来同步序号。当
SYN=1而ACK=0时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使SYN=1和ACK=1。 因此,SYN置1就表示这是一个连接请求或连接接受报文。ACK: 即是确认字符,在数据通信中,服务器发给客户端的一种传输类控制字符。表示发来的数据已确认接收无误。
TCP协议规定,只有ACK=1时有效,也规定连接建立后所有发送的报文的ACK必须为1。FIN (finis):完,终结的意思, 用来释放一个连接。当
FIN = 1时,表明此报文段的发送方的数据已经发送完毕,并要求释放连接。
发送 HTTP 请求
与服务器建立连接后,客户端就向服务器发起请求,产生HTTP请求报文。
一个HTTP请求报文由请求行request line、请求头部header、空行和请求数据4个部分组成。
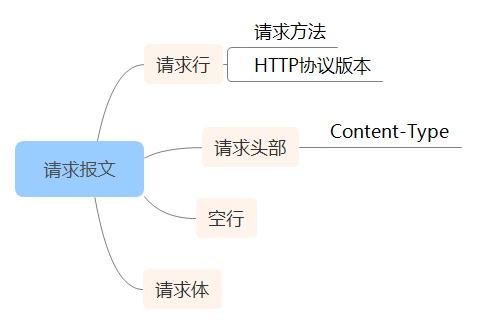
请求头部,紧接着请求行之后的部分,用来说明服务器要使用的附加信息;
空行,请求头部后面的空行是必须的;
请求体,可以添加任意的其他数据;
通过报文还可以看到更多具体信息,这里就不进一步分析报文了。
服务器处理请求
服务器接受到客户端发送的HTTP请求后,查找客户端请求的资源,并返回响应报文。
访问资源可以是访问静态资源,这个就直接根据URL地址去服务器里找即可;如果访问动态资源的话要经过一个叫 CGI 的东西,再用服务端脚本处理,再返回给客户端。

服务器在处理完请求后,返回一个HTTP响应报文。
HTTP响应报文和请求报文的结构差不多,也是由四个部分组成:状态行、消息报头、空行、响应体。
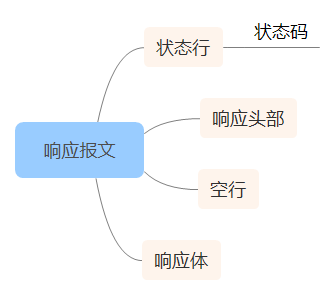
- 1xx:指示信息 – 表示请求已接收,继续处理
- 2xx:成功 – 表示请求已被成功接收、理解、接受
- 3xx:重定向 – 要完成请求必须进行更进一步的操作
- 4xx:客户端错误 – 请求有语法错误或请求无法实现
- 5xx:服务器端错误 – 服务器未能实现合法的请求
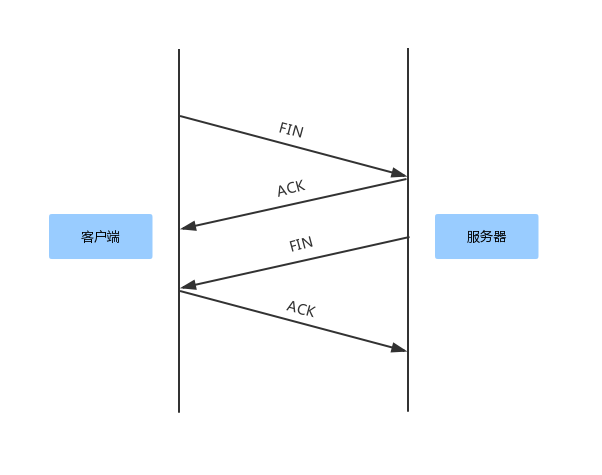
关闭 TCP 连接
为了避免服务器与客户端双方的资源占用和损耗,当双方没有请求或响应传递时,任意一方都可以发起关闭请求。与创建TCP连接的3次握手类似,不过关闭TCP连接,需要4次握手。
页面渲染
在服务器返回的响应报文中,响应体主要由HTML、CSS、JS,以及图片、视频等各种媒体资源。如果说响应的内容是HTML文档的话,就需要浏览器进行解析和渲染最后再呈现给用户。整个过程需涉及两个方面:解析和渲染。
浏览器解析 HTML
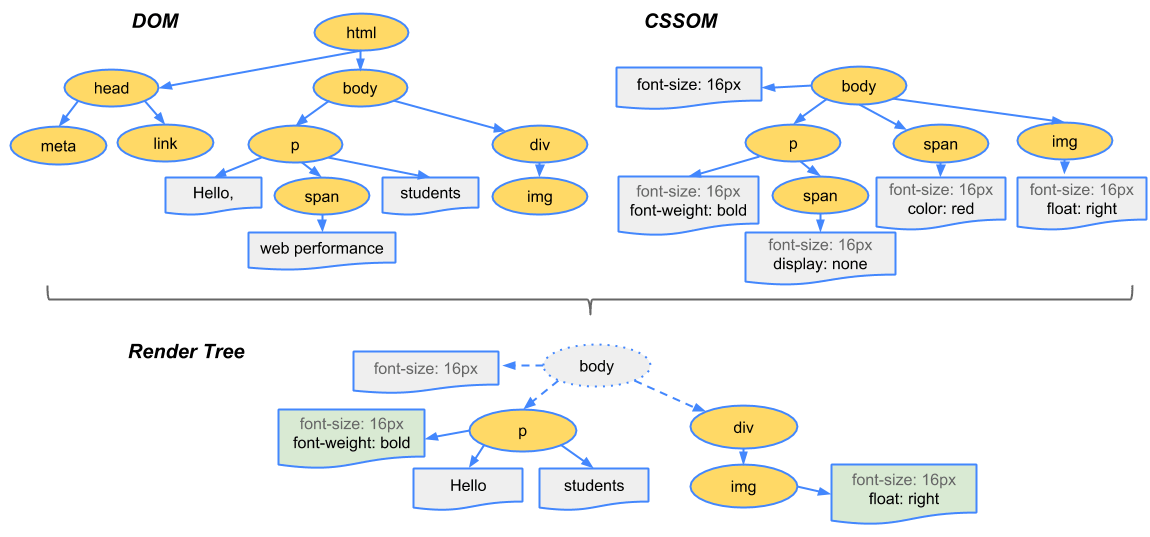
当浏览器获得一个HTML文件时,浏览器会将HTML解析成一个DOM树,DOM树的构建过程是一个深度遍历过程,当前节点的所有子节点都构建好后才会去构建当前节点的下一个兄弟节点。解析CSS成CSS规则数,CSS选择符是从右到左进行匹配的。然后通过DOM树和CSS规则树Rule Tree来构造渲染树Rendering Tree。
Rendering Tree渲染树与DOM树不同,渲染树中并没有head、display:none等不必显示的节点。
注意
visibility: hidden与display: none是不一样的。前者隐藏元素,但元素仍占据着布局空间(即将其渲染成一个空框),而后者 (display: none) 将元素从渲染树中完全移除,元素既不可见,也不是布局的组成部分。
浏览器渲染页面
有了Render Tree,浏览器已经能知道网页中哪些节点应该是可见的以及它们的计算样式,但尚未计算它们在设备视口内的确切位置和大小—这就是“布局”阶段,也称为“自动重排”。
为弄清每个对象在网页上的确切大小和位置,浏览器从渲染树的根节点开始进行遍历。
需要注意的是:上述过程是逐步完成的,为了更好的用户体验,渲染引擎会尽可能早的将内容呈现到屏幕上,并不会等到所有的html都解析完成之后再去构建和布局render树。这个过程是循序渐进的,浏览器解析完一部分内容就显示一部分内容,同时还可能通过网络下载其他资源内容。
根据渲染树布局,计算CSS样式,即每个节点在页面中的大小和位置等几何信息。HTML默认是流式布局的,CSS和JS会打破这种布局,改变DOM的外观样式以及大小和位置。这就触发浏览器进行Repaint重绘、Reflow回流。
Repaint(重绘):只改变某个元素的背景颜色、文字样式,不影响整体布局,浏览器将Repaint,重画屏幕某一部分
Reflow(回流):当某个元素发生了变化影响了整体布局,浏览器将需要倒回去重新渲染
Reflow比Repaint更花费时间,也就是更影响性能。所以在写代码的时候尽量避免过多的Reflow。
减少 Reflow / Repaint
- 采用
ClassName修改DOM,减少重绘 - 对于动画的
HTML,可使其脱离文档流,修改CSS不会导致回流 - 避免使用
table布局,避免修改布局导致回流
最后浏览器绘制各个节点,将页面渲染到屏幕上。
总结
边写边思考,不断在补充。我发现这个话题可以延伸的太多太多了,无论是广度还是深度都还可以继续扩展,总结完全篇感觉还差很多,我仅限站在自己理解的角度上去堆积式的总结,以后待更新。